Some friends were registered to this CTF, and since I had some days off, I decided to work a bit on one RE exercise.
The binary is called BadVM:
[nathan@Jyn badvm]$ ./badvm-original
### BadVM 0.1 ###
Veuillez entrer le mot de passe:
toto
Ca mouline ...
Plus qu'un instant ... On avait la réponse depuis le début en faite :>
Perdu ...
It is a stripped, ELF 64 PIE binary. Time to start Binary Ninja. This binary has no anti-debug, nor packing techniques. Just some calls to sleep. Once these calls NOPed, we can start reversing the VM.
The VM is initialized in the function I called load_vm (0xde6). Then, the function at 0xd5f is called, let’s call it vm_trampoline.
This function will choose the next instruction to execute. Load it’s address in rax and call it. vm_trampoline is called at the end of each instruction. Thus, each instruction is a new entry in the backtrace.
This means, when returning from the first call to vm_trampoline, we can read the result and return it. This takes us back to load_vm, and result is checked.
In case of an invalid character in the password, we have an early-exit. Input is checked linearly, no hash or anything, Thus instruction counting works well.
Since I was on holidays, I decided to experiment a bit with lldb, and write a instrument this VM using its API.
Reversing the VM
This VM uses 0x300 bytes long buffer to run. Some points of interest:
- 0x4: register A (rip)
- 0x5: register B
- 0xFF: register C (result)
- 0x2fc: register D
-
0x2fe: register E (instruction mask?)
- 0x32: password buffer (30 bytes)
- 0x2b: data buffer (xor data, 30 bytes)
- 0x200: data start (binary’s .data is copied in this area)
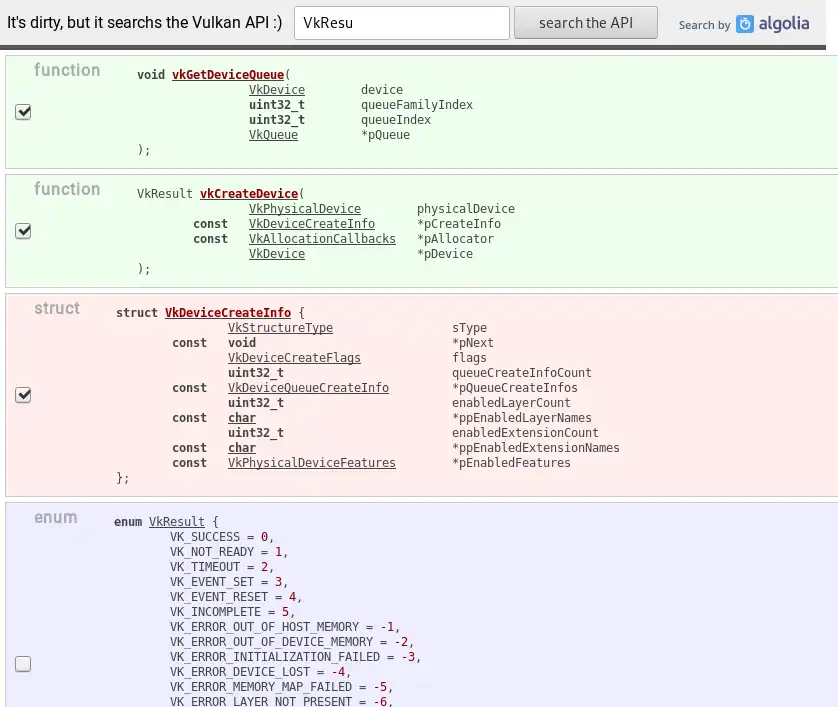
Instruction are encoded as follows:
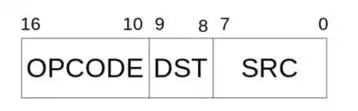
To select the instruction, the VM contains a jump-table.
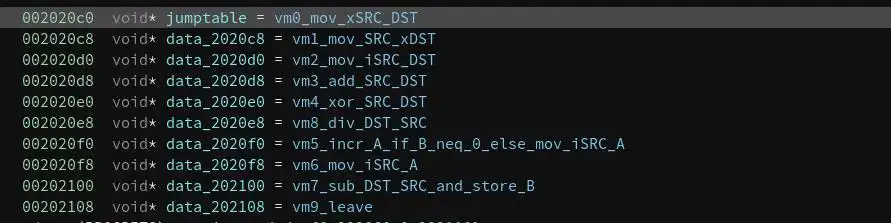
Here one of the instructions (a ~GOTO):
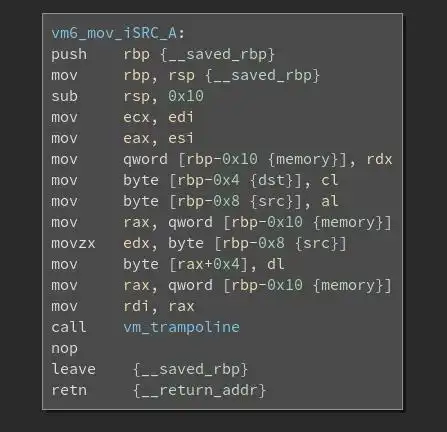
Final note: each instruction/function has the following prototype:

Instrumenting using LLDB
This VM does not check its own code, thus we can freely use software breakpoints. The code is not rewritten, thus offsets are kept. This allow us to simply use LLDB’s python API to instrument and analyse the VM behavior.
First step, create an lldb instance:
def init():
dbg = lldb.SBDebugger.Create()
dbg.SetAsync(True)
console = dbg.GetCommandInterpreter()
error = lldb.SBError()
target = dbg.CreateTarget('./badvm', None, None, True, error)
# check error
info = lldb.SBLaunchInfo(None)
process = target.Launch(info, error)
print("[LLDB] process launched")
Now, we can register out breakpoints. Since vm_trampoline is called before each instruction, we only need this one:
target.BreakpointCreateByAddress(p_offset + VM_LOAD_BRKP_OFFSET)
Now, we can run. To interact with the binary, we can use LLDB’s events. Registering a listener, we can be notified each time the process stops, or when a breakpoint is hit.
listener = dbg.GetListener()
event = lldb.SBEvent()
if not listener.WaitForEvent(1, event):
continue
if event.GetType() != EVENT_STATE_CHANGED:
# handle_event(process, program_offset, vm_memory, event)
continue
regs = get_gprs(get_frame(process))
if regs['rip'] - program_offset != address:
print("break location: 0x{:x} (0x{:x})".format(
regs['rip'] - program_offset, regs['rip']))
To read memory, or registers, we can simply do it like that
process.ReadUnsignedFromMemory(vm_memory + 0, 1, err),
process.selected_thread.frame[frame_number].registers
# registers[0] contains general purpose registers
Now we can implement a pretty-printer to have “readable” instructions. Once everything together, we can dump the execution trace:
mov [0x00], 0xff
mov [0x01], 0x01
mov tmp, [0x00] # tmp=0xff
mov [tmp], [0x01] # src=0x1
mov [0x00], 0x0b
mov [0x01], 0x1d
mov tmp, [0x00] # tmp=0xb
mov [tmp], [0x01] # src=0x1d
mov [0x01], 0x0b
mov tmp, [0x01] # tmp=0xb
mov [0x00], [tmp] # [tmp]=0x1d
mov r5, [0x00]
sub r5, [0x0a] # 0x1d - 0x0 = 0x1d
if r5 == 0:
mov rip, 0x2d
mov [0x01], 0x0a
[...]
Now, we can reverse the program running in the VM:
def validate(password, xor_data):
if len(password) != len(xor_data):
return -1
D = 0
for i in range(len(xor_data)):
tmp = (D + 0xAC) % 0x2D
D = tmp
if xor_data[i] != chr(ord(password[i]) ^ tmp):
return i
return len(xor_data)
And we get the flag:
SCE{1_4m_not_4n_is4_d3s1yn3r}
Conclusion
This VM has no anti-debug, packing or anything special. But it was a funny binary to reverse. To instrument the VM, lldb is useful, but using DynamiRIO would be a more elegant method.